在介绍sync时,已经了解到Java中线程的创建以及上下文切换是比较消耗性能的,因此引入了偏向锁,轻量级锁等优化技术,目的是减少用户态和核心态之间的切换频率。
但是在这些优化基础上,我们还可以想到既然创建和销毁很消耗性能,那么线程能不能复用 ?所以引出了线程池 。
另外,线程的创建需要开辟虚拟机栈,本地方法栈,程序计数器等线程私有的内存空间,在线程销毁时需要回收这些系统资源,频繁地创建销毁线程会浪费大量资源,而通过复用已有线程可以更好地管理和协调线程的工作。
线程池主要解决两个问题:
解释说明:
在JDK中提供了一个线程池的工厂类—Executors。在Executors中定义了多个静态方法,用来创建不同配置的线程池,常见的有以下几种
创建一个单线程化的线程池,它只会用唯一的工作线程来执行任务,保证所有任务按先进先出的顺序执行。
public class CreateSingleThreadPool{
public static void main(~) throw~{
//创建单线程池
ExecutorService singleThreadExecutor = Executors.newSingleThreadExecutor();
for(int i=1;i<=5;i++){
final int taskId = i;
//向线程池中提交任务
singleThreadExecutor.submit(new Runnable(){
@Override
public void run(){
println(curThread + taskId);
}
});
Thread.sleep(1000);
}
}
}
执行后可以看到,所有的task始终是在同一个线程中被执行的。
创建一个可缓存线程池,如果线程池长度超过处理需要,可灵活回收空闲线程,若无可回收,则新建线程。
public class CreateCacheThreadPool{
public static void main(~) throw~{
ExecutorService cachedThreadPool = Executors.newCacheThreadPool();
for(int i=1;i<=5;i++){
final int taskId = i;
//Thread.sleep(1000);
cachedThreadPool.execute(new Runnable(){
@Override
public void run(){
println(curThread + taskId);
Thread.sleep(500);
}
});
}
}
cachedThreadPool.shutdown();
}
执行的效果如下,缓存线程池会创建新的线程来执行任务
pool-1-thread-1 正在执行task 0
pool-1-thread-4 正在执行task 3
pool-1-thread-3 正在执行task 2
pool-1-thread-2 正在执行task 1
pool-1-thread-5 正在执行task 4
但是如果修改下代码,在提交任务之前休眠1s,那么将不同。
再次执行结果同SingleThreadPool一致,因为提交的任务只需要500ms即可完成,休眠1s导致在新的任务提交之前,线程已经处于空闲状态,可以被复用执行任务。
创建一个固定数目的,可重用的线程池
public class CreateFixThreadPool{
public static void main(~) throw~{
//创建线程数量为3的线程池
ExecutorService singleThreadExecutor = Executors.newFixedThreadPool(3);
//提交10个任务给线程池执行
for(int i=1;i<=10;i++){
final int taskId = i;
singleThreadExecutor.submit(new Runnable(){
@Override
public void run(){
println(curThread + taskId);
}
});
}
}
}
上述代码创建了一个固定数量3的线程池,因此虽然向线程池提交了10个任务,但是这10个任务只会被3个线程分配执行。
创建一个定时线程池,支持定时及周期性任务执行(精确的还是需要lock来,线程池会因为设备休眠原因导致时间不准确或者不执行)
public class CreateScheduledThreadPool{
public static void main(~) throw~{
//创建线程数量为4的定时线程池
ScheduleExecutorService scheduleThreadPool = Executors.newScheduleThreadPool(4);
//延迟1s执行,,每隔1s执行一次
scheduleThreadPool.scheduleAtFixedRate(new Runnabel(){
run(){
Date now = new Date();
println(curThread + now);
}
},500,500,millseconds);
}
Thread.sleep(5000);
//使用shutdown关闭定时任务
scheduleThreadPool.shutdown();
}
上面代码创建了一个线程数量为2的定时任务线程池,通过scheduleAtFixedRate方法,指定每隔500ms执行一次任务,并且在5s之后通过shutdown关闭定时任务。
但是!阿里的Java开发手册中已经禁止使用Executors来创建线程池,原因如下
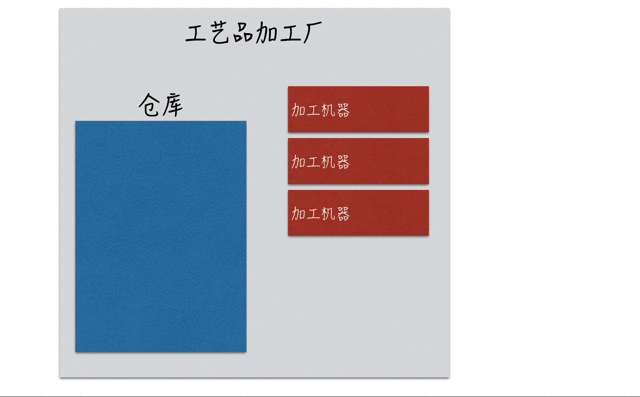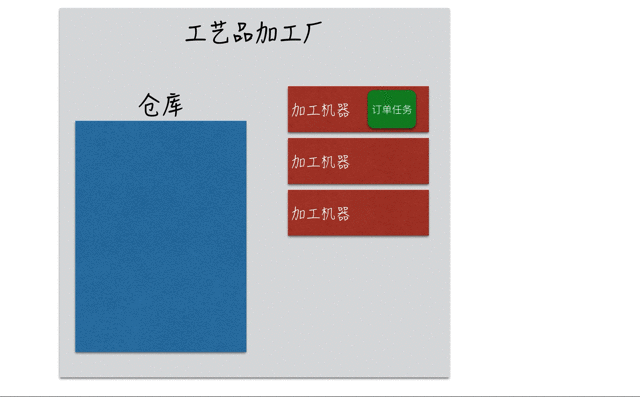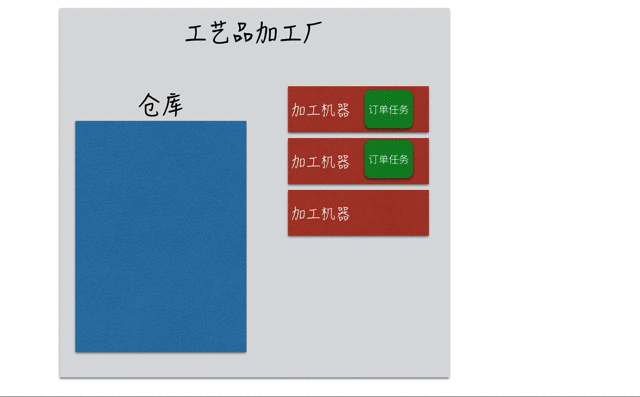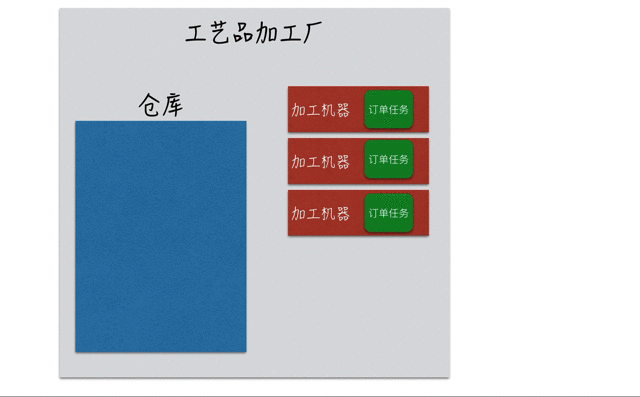
以一个生活中的实际案例来描述。某加工厂有3台加工机器用来生产订单所需的产品,正常情况下3台机器能够保证所有订单按时按需生产完,如下图:
如果订单量突然大幅增加,3台机器已经处于满负荷状态,一时间无法完成新增的订单任务。那么只能硬着头皮接下新来的订单,但是会将新来的订单暂存在仓库中,当有加工机器空闲下来之后,再用来生产仓库中的订单,如下图:

如果订单量持续快速增加,导致仓库也存储满了。那么就会增加新机器来满足订单需求,如下图:
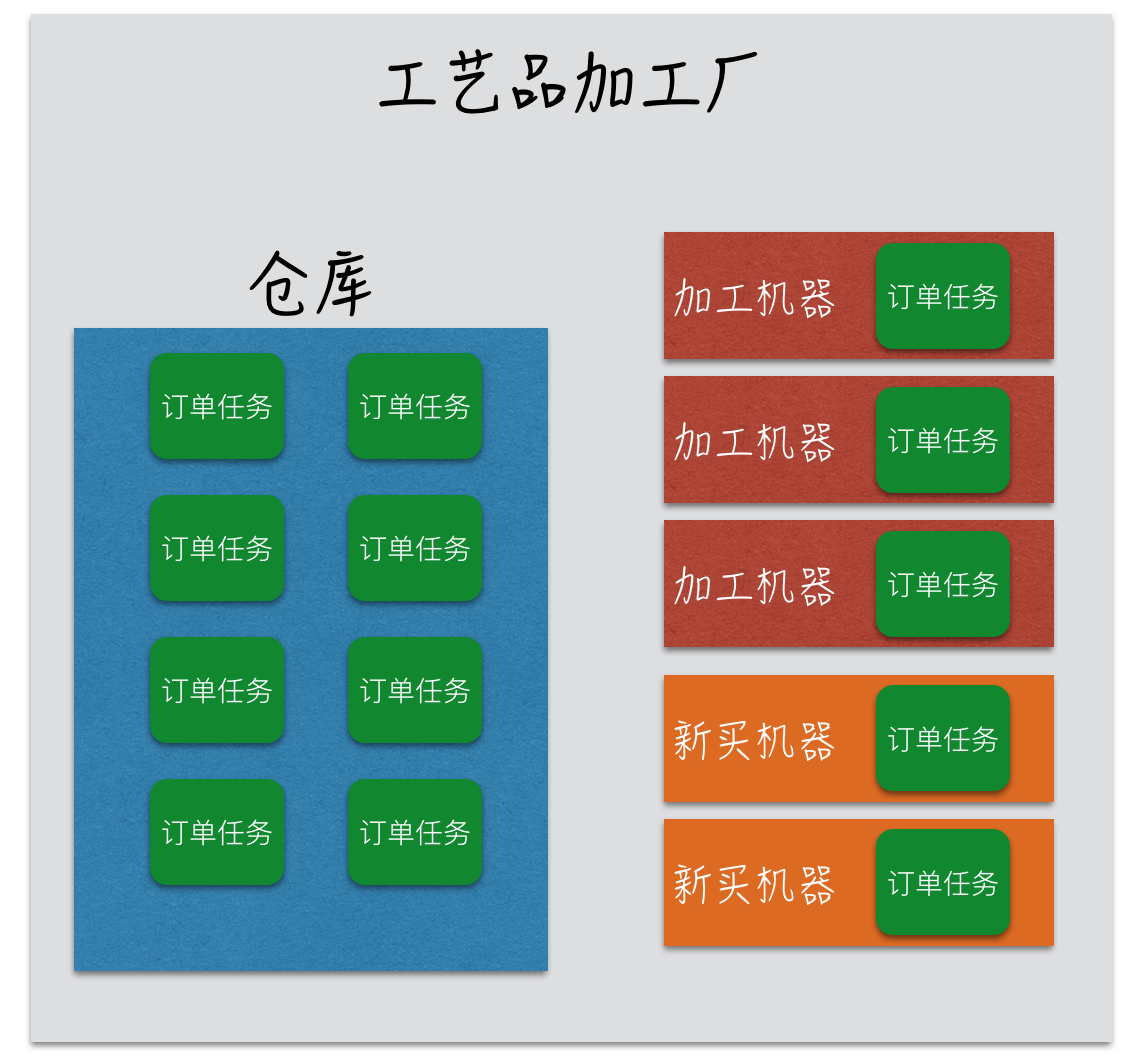
有了仓库和新购买的机器加持,加工厂还是能正常运转的。但是当某些极端情况发生,比如双十一之后订单爆单了。这是新增的订单任务连仓库以及所有的加工机器都已经无法容纳,说明工厂已经不能再接受新订单了,因此只能拒接所有新的订单。
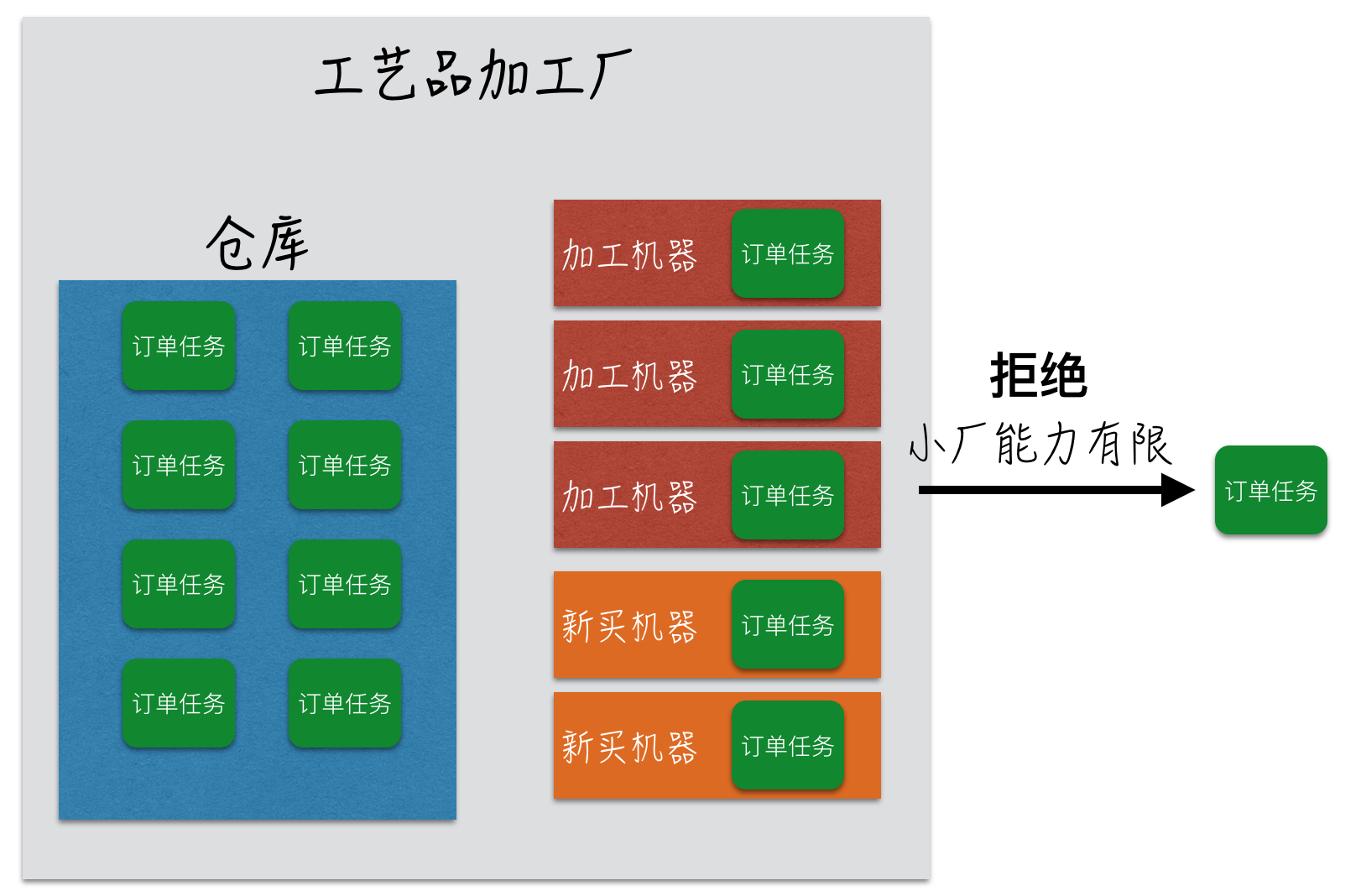
线程池的工作流程同上面描述的加工厂完成订单任务非常相似,并且在线程池的构造器中,通过传入的参数可以设置默认有多少台加工机器,仓库的大小,可以购买新的加工机器的最大数量等。

从上图中可以大体看出,在线程池内部主要包含以下几个部分:
worker集合:保存所有的核心线程和非核心线程(类比加工厂的加工机器),其本质是一个HashSet
private final HashSet<Worker> workers = new HashSet<>;
等待任务队列:当核心线程个数达到corePoolSize时,新提交的任务会先被保存在等待队列中(类比加工厂中的仓库),其本质是一个阻塞队列BlockingQueue
private final BlockingQueue<Runnable> workQueue;
ctl:是一个AtomicInteger类型,二进制高3位用来标识线程池的状态,低29位用来记录池中线程数量
获取线程池状态,工作线程数量,修改ctl的方法分别如下:
private final AtomicInteger ctl = new AtomicInteger(ctlof(RUNNING,0));
//计算当前运行状态
private static runStateOf(int c){return c&-CAPACITY}
//计算当前线程数量
private static workCountOf(int c){return c&CAPACITY}
//通过状态和线程数生成ctl
private static ctlOf(int rs,int wc){return rs|wc}
线程池主要有以下几种状态:

构造参数说明:
当ThreadPoolExecutor的allowCoreThreadTimeOut设置为true时,核心线程超时后也会被销毁。
当我们调用execute或submit,将一个任务提交给线程池,线程池收到这个任务请求后,有以下几种处理情况:
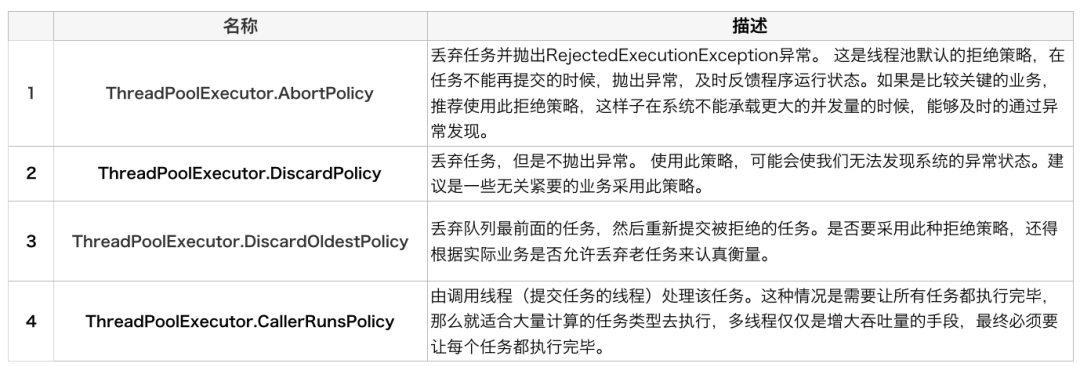
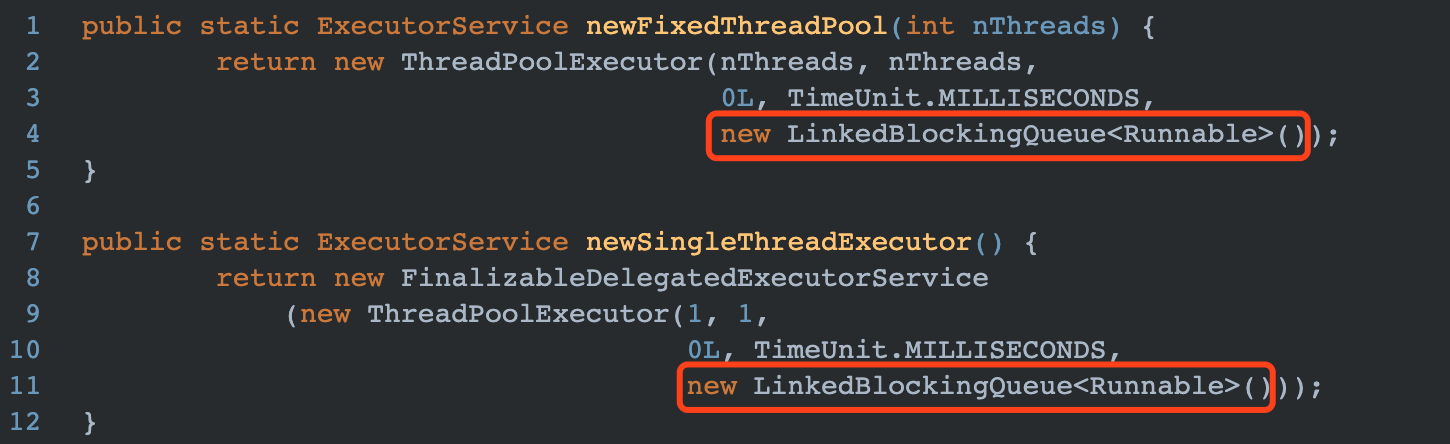
可以看到传入的是一个无界的阻塞队列,理论上可以无限添加任务到线程池。当核心线程执行时间很长,则新提交的任务还在不断的插入到阻塞队列中,最终造成OOM。

可以看到,缓存线程池的最大线程数为Integer最大值。当核心线程耗时很久,线程池会尝试创建新的线程来执行提交的任务,当内存不足时就会报无法创建线程的错误。
